
 Einen simplen WebCrawler in C# programmieren
Einen simplen WebCrawler in C# programmieren
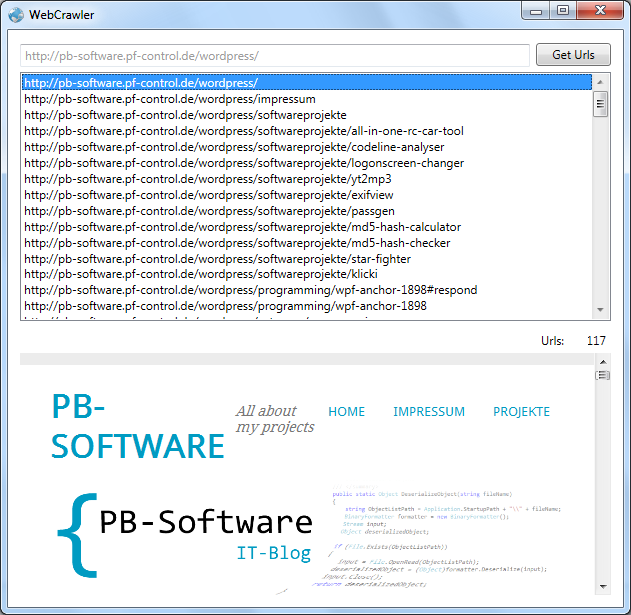
Wie programmiert man einen simplen WebCrawler in C#? Diese Frage habe ich mir gestellt und an sich ist es relativ simpel. Erstes Ziel war es, von einer beliebigen Webseite die vorhandene Urls auszulesen und anzeigen zu lassen.
Man gibt also eine Webadresse (z.B. https://www.codefieber.de an und diese wird einer Funktion übergeben, welche einen Request an die Webadresse schickt. Läuft alles glatt (also erscheint kein 404 Fehler) dann wird als Response die Webseite in Form eines HTML-Strings zurückgeliefert.
Folgender Code würde z.B. dafür funktionieren:
public string GetResponsetHtmlStr(string url, string startUrl)
{
string htmlStr = "";
this.startUrl = startUrl;
try
{
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(url);
WebRequest webRequest = (WebRequest)httpWebRequest;
webRequest.Proxy = null;
WebResponse webResponse = webRequest.GetResponse();
StreamReader sr = new StreamReader(webResponse.GetResponseStream());
htmlStr = sr.ReadToEnd();
}
catch (WebException ex)
{
throw ex;
}
return htmlStr;
}
Diesen HTML-String kann man nun per RegEx durchlaufen und nach “href=”-Links suchen lassen. Wenn welche gefunden werden, dann sollen diese in einer string-List gespeichert werden und diese Liste wird zum späteren auflisten der Links zurück gegeben.
public List<string> GetUrlList(string htmlStr)
{
string linkedUrl;
List<string> urlList = new List<string>();
Regex regexLink = new Regex("(?<=<a\\s*?href=(?:'|\"))[^'\"]*?(?=(?:'|\"))");
foreach (var match in regexLink.Matches(htmlStr))
{
if (!urlList.Contains(match.ToString()))
{
linkedUrl = GetLinkedUrl(match.ToString());
urlList.Add(linkedUrl);
}
}
return urlList;
}
Da manche Urls einfach nur mit z.B. “/worpress…./irgendeineseite.html” anfangen, müssen wir um aus dieser Url eine weitere Response holen zu können die Start-Url vorne anhängen, dies geht folgendermaßen:
private string GetLinkedUrl(string url)
{
if (!url.Contains("http://"))
{
if (url.IndexOf("/", 0) != -1)
{
url = this.startUrl + url;
}
else
{
url = this.startUrl + "/" + url;
}
}
return url;
}
Nun könnte man eine Gui bauen, mit der man diese Informationen, also die UrlList wieder ausliest und z.B. in einer ListView anzeigt.
Klickt man nun auf einen Link, wird von dem Link ein Request angefragt und wenn kein Fehler entsteht, wird wieder eine Response zurückgegeben. Somit kann immer tiefer eine Webseite gecrawlet werden.
Der komplette Crawler Library Code sieht folgendermaßen aus:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Net;
using System.IO;
using System.Text.RegularExpressions;
namespace CrawlerLib
{
public class Crawler
{
string startUrl;
/// <summary>
/// Hole Response als HTML-String
/// </summary>
/// <param name="url">Übergeben Url</param>
/// <param name="startUrl">Übergeben Start Url</param>
/// <returns>HTML-String</returns>
public string GetResponsetHtmlStr(string url, string startUrl)
{
string htmlStr = "";
this.startUrl = startUrl;
try
{
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(url);
WebRequest webRequest = (WebRequest)httpWebRequest;
webRequest.Proxy = null;
WebResponse webResponse = webRequest.GetResponse();
StreamReader sr = new StreamReader(webResponse.GetResponseStream());
htmlStr = sr.ReadToEnd();
}
catch (WebException ex)
{
throw ex;
}
return htmlStr;
}
/// <summary>
/// Durchsuche den HTML-String nach href-Links,
/// füge diese einer Liste hinzu und gebe die Liste
/// zurück
/// </summary>
/// <param name="htmlStr">HTML-String</param>
/// <returns>Url-Liste</returns>
public List<string> GetUrlList(string htmlStr)
{
string linkedUrl;
List<string> urlList = new List<string>();
Regex regexLink = new Regex("(?<=<a\\s*?href=(?:'|\"))[^'\"]*?(?=(?:'|\"))");
foreach (var match in regexLink.Matches(htmlStr))
{
if (!urlList.Contains(match.ToString()))
{
linkedUrl = GetLinkedUrl(match.ToString());
urlList.Add(linkedUrl);
}
}
return urlList;
}
/// <summary>
/// Überprüfe ob die Url nur mit /..../irgendeineseite.html
/// beginnt, wenn ja füge die Start-Url hinzu um später eine
/// korrekte Response zu erhalten
/// </summary>
/// <param name="url">übergebene Url</param>
/// <returns>Fertige Url</returns>
private string GetLinkedUrl(string url)
{
if (!url.Contains("http://"))
{
if (url.IndexOf("/", 0) != -1)
{
url = this.startUrl + url;
}
else
{
url = this.startUrl + "/" + url;
}
}
return url;
}
/// <summary>
/// Gibt einen Link mit http:// zurück, sofern
/// die Url kein http:// besitzt. Ansonsten
/// funktioniert der Request nicht
/// </summary>
/// <param name="url">Die zu überprüfende Url</param>
/// <returns>Fertige überprüfte Url</returns>
public string GetCheckedUrl(string url)
{
if (!url.Contains("http://"))
{
if (!url.Contains("https://"))
{
url = "http://" + url;
}
}
return url;
}
/// <summary>
/// Vergleiche Url Listen, damit nur neue Links hinzugefügt werden
/// Keine doppelten Links
/// </summary>
/// <param name="urlList1">Alte Url-Liste</param>
/// <param name="urlList2">Neue Url-Liste</param>
/// <returns>Verglichene Liste mit allen neuen Links</returns>
public List<string> CompareUrlInList(List<string> urlList1, List<string> urlList2)
{
List<string> newComparedList = urlList2.Except(urlList1).ToList();
return newComparedList;
}
}
}
23 Juli, 2015 um 15:42
Hallo Pascal,
vielen Dank für dein Post.
Leider verseteh ich nicht was bei deiner Methode GetResponserHtmlStr die Parameter url und startUrl angeben sollen?
Der Parameter url ist ja logisch, da wird die url übergeben, aber für was ist startUrl?
23 Juli, 2015 um 16:14
Hey,
da das nun schon ziemlich lange her ist, wo ich das gemacht habe – und jetzt auch nicht mehr recht weiß was ich mir dabei gedacht habe, habe ich mal eben in den Code geschaut.
Im Grunde ist das die selbe URL. Die an sich dort in der Methode nicht verwendet wird, insofern ist sie dort überflüssig. Der Hintergrund dabei ist allerdings, dass ich die StartURL mit der zweiten URL vergleiche um nicht doppelte URLs angezeigt zu bekommen. Ich glaube ich muss mir das nochmal genauer anschauen.
24 Juli, 2015 um 14:43
Hallo Pascal,
okay ja das dachte ich mir auch.
Ich habe deinen code als Grundbaustein genutzt.
Und das hat mich ein wenig verwirrt.
Vielen Dank für die schnelle Antwort.